

Le tecniche di Intelligenza Artificiale per l’analisi dei Big Data: il Machine Learning
In questo articolo affronteremo in maniera introduttiva le tematiche legate al Machine Learning – da intendersi come branca dell’Intelligenza Artificiale – che riscuotono crescente attenzione tra i vari centri di ricerca tecnologica.
L’intelligenza artificiale è tra le principali innovazioni tecnologiche degli ultimi anni e sta assumendo sempre più un ruolo rilevante. Numerose aziende e centri di ricerca, infatti, manifestano interesse per questa materia, cercando, da un lato, di comprenderne gli approcci e i principi e, dall’altro, di analizzarne i vari ambiti di applicazione.
Lo studio delle tecniche di Machine Learning applicate all’analisi dei Big Data prevale tra le principali attività di ricerca e sviluppo in ambito tecnologico, con l’obiettivo di renderle un punto fermo per l’analisi e l’interpretazione dei Big Data.

Nell’ambito dell’articolo, tratteremo i seguenti punti:
- Introduzione al concetto di Intelligenza Artificiale
- Principi e Algoritmi del Machine Learning
- Reti Neurali e Deep Learning
- Strumenti e applicazioni

Introduzione al concetto di Intelligenza Artificiale
Cos’è il Machine Learning
L’Intelligenza artificiale (AI) è quella tecnologia che ha l’obiettivo di riprodurre in modo informatico le modalità di ragionamento, apprendimento e scelta tipiche degli esseri umani. Le tecniche di Intelligenza Artificiale apprendono da situazioni conosciute e consolidate per poi produrre previsioni. I primi approcci a tale disciplina possono essere ricondotti già alla metà degli anni ’50 del ventesimo secolo, quando è stato sviluppato il primo programma (Logic Theory Machine)[1] in grado di riprodurre teoremi matematici con la definizione e la messa in atto di operazioni logiche.
Una delle più famose definizioni sul Machine Learning è stata riformulata da Tom M. Mitchell riprendendo Arthur L. Samuel, che per primo coniò il termine nel 1959:
“Si dice che un programma impara da una certa esperienza E rispetto a una classe di compiti T ottenendo una performance P, se la sua performance nel realizzare i compiti T, misurata dalla performance P, migliora con l’esperienza E.”
Negli anni, i campi di applicazione dell’Intelligenza Artificiale si sono ampliati notevolmente, soprattutto grazie allo sviluppo di nuovi processori, nuovi dispositivi di memorizzazione e ai progressi fatti nel settore della robotica. Uno degli ambiti in cui il concetto di Intelligenza Artificiale trova una delle sue massime espressioni è sicuramente quello del Machine Learning.
L’apprendimento automatico, o appunto Machine Learning, può essere considerato un sottoinsieme della computer science dove i sistemi informatici e gli algoritmi hanno come principale obiettivo l’apprendimento tramite l’interpretazione dei dati (Big Data, ossia grandi quantità di dati che al loro interno contengono un valore informativo, potenzialmente inestimabile), sintetizzando e creando da essi nuova conoscenza, tramite modelli predittivi in cui gli algoritmi sono alimentati da istruzioni dinamiche e non più statiche.
Il Machine Learning è la sintesi di mondi diversi ma complementari: matematica, statistica, probabilità, informatica.
A dimostrazione dell’importanza di tale sezione dell’informatica, sono notevoli gli investimenti che le aziende del settore tecnologico, negli ultimi anni, destinano allo sviluppo delle tecniche del Machine Learning (circa il 60% dei finanziamenti diretti all’Intelligenza Artificiale) [2] , così come l’Unione Europea ha dichiarato un piano di investimento in AI per arrivare a circa 20 miliardi di euro l’anno a partire dal 2021 [3].
Principi e Algoritmi del Machine Learning
Analisi del problema
Per poter formalizzare in modo corretto uno studio di Machine Learning risulta necessario, come passo iniziale, applicare i suoi algoritmi su un modello connesso ad un eventuale problema da risolvere o esigenza da soddisfare. Infatti, una volta evidenziato il problema, è fondamentale creare un processo di interazione tra le diverse figure del progetto che avranno background e competenze complementari tra loro.
Spesso chi produce e possiede i dati non ha le competenze tecniche per interpretarli e di conseguenza collabora con terzi che, tramite strumenti analitici e statistici, provvedono a comprenderne le informazioni intrinseche e ad estrarre insight.
Questo interscambio di informazioni permette di ottenere una visione completa ed integrata fondamentale per procedere ai vari task di apprendimento del Machine Learning.
Tipi di problema e task
I task di apprendimento del Machine Learning sono raggruppabili in tre macrocategorie ognuna con specifiche caratteristiche che sono alla base dell’intero sistema di comprensione della macchina:
- Apprendimento supervisionato: questa categoria prevede la presentazione al computer di specifici input di esempio e gli output prodotti, con l’idea di far generare al sistema informatico una regola generale in grado di riprodurre e mappare il processo input-output.
- Apprendimento non supervisionato: in questo caso al computer vengono forniti solamente dati di input con l’obiettivo di poter spingere la macchina informatica a definire una struttura partendo dai soli dati in ingresso. Il vero scopo è quello di conoscere schemi nascosti all’interno dei dati iniziali ed estrapolarli tramite le tecniche di ML.
- Apprendimento con rinforzo: la macchina informatica viene fatta interagire con un ambiente dinamico in cui c’è uno scopo da raggiungere (es: guida di un’auto). Il computer, in questo modo, inizierà ad analizzare l’ambiente e il relativo problema e gli verranno forniti feedback positivi o negativi in modo da orientarlo verso la migliore soluzione legata all’azione richiesta.
La classificazione dei task secondo l’output atteso
La classificazione secondo l’output atteso è un’altra modalità con cui è possibile classificare le diverse categorie di task, infatti il raggruppamento in questo caso viene fatto secondo l’output atteso dal processo di machine learning.
In questo ambito, le categorie principali sono:
- La classificazione: con questo tipo di categoria si determina in quale classe appartiene un determinato input sulla base di regole di classificazione prodotte dal sistema di apprendimento, che, in questo caso, è legato alle tecniche di quello supervisionato. Tra i principali algoritmi usati per questo problema citiamo “il classificatore Bayesiano”[4], “Regressione Logistica[5],” “SVM”, “Nearest Neighbor”, “Decision Tree”[6].
- La regressione: questa categoria è tipicamente legata all’apprendimento supervisionato e può essere intesa come la classificazione sopra citata ma con l’unica differenza che l’output presenta un dominio continuo e non statico. Tra le principali tipologie di regressione possiamo citare la Regressione Lineare Semplice, Regressione Lineare Multipla e Regressione Logistica.
- Clustering: questo insieme di algoritmi è da ricondurre alle tecniche di apprendimento non supervisionato, dato che non richiedono un addestramento preliminare della macchina informatica, poiché quest’ultima cerca una suddivisone naturale, in cluster, in base alla similarità dei campioni che formano l’insieme analizzato.
Le fasi del processo di Machine Learning
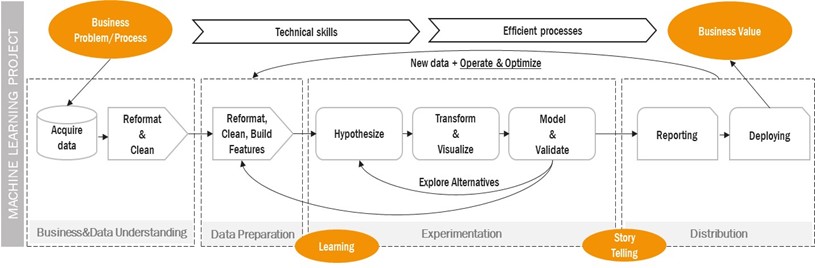
Dopo aver discusso le tipologie di apprendimento e di task del Machine Learning, di seguito andiamo a fissare le principali fasi che ne compongono il processo di attuazione. Uno degli approcci più utilizzati nel settore è sicuramente quello del ASUM-DM (Analytics Solutions Unified Method for Data Mining)[7], un processo standardizzato che può essere semplificato in quattro fasi che agiscono in maniera consecutiva creando un processo iterativo:
- Business & Data Understanding: fase di comprensione del problema di business e della semantica dei dati da utilizzare nei modelli, nonché fase di identificazione della variabile target quale oggetto della predizione. È una fase di grande importanza proprio perché costituisce la base dell’architettura di tutto il processo di Machine Learning.
- Data Preparation: la più dispendiosa in termini di effort (~70%), tale fase consiste nella creazione delle features e nella costruzione degli asset che il modello combina nella fase successiva di sperimentazione per l’ottenimento di predizioni sulla variabile target.
- Experimentation: creazione di modelli di Machine Learning per la predizione della variabile target. Le performance predittive ottenute dalle sperimentazioni vengono opportunamente valutate, guidano nella ricerca di nuove features predittive e orientano i nuovi esperimenti.
- Distribution: il modello con le migliori performance predittive e che ben risponde ai requisiti del business può essere distribuito in ambiente di produzione mediante tool di data visualization.
Reti Neurali e Deep Learning
Dopo aver introdotto i processi e le modalità di apprendimento del Machine Learning, risulta necessario analizzare le sue diramazioni, che si presentano come algoritmi avanzati rispetto a quelli tradizionali e di conseguenza in grado di risolvere problemi ancor più complessi. È utile ricordare come, alla base di questa tecnologia di Intelligenza Artificiale, ci sia sempre lo studio del sistema neurale degli esseri umani, con l’obiettivo di riprodurne in maniera artificiale l’intero meccanismo.
Approccio alle Reti neurali artificiali
Le reti neurali sono da considerarsi come un modello di apprendimento che sostanzialmente cerca di replicare il funzionamento del cervello umano, dove ogni neurone riceve impulsi nervosi attraverso i dendriti, poi compie alcuni “calcoli” e trasmette la risposta tramite una serie di conduttori ad impulsi (gli assoni).
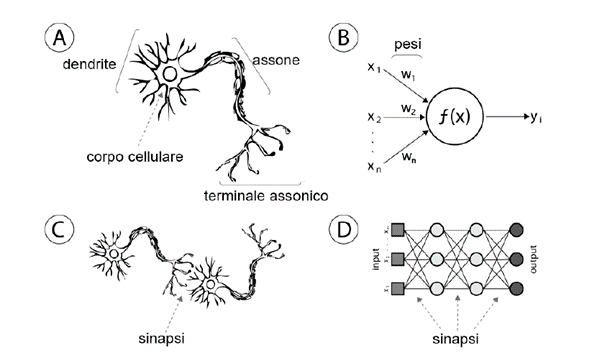
Come illustrato nella figura, il neurone artificiale (B, D), agisce allo stesso modo di quello biologico (A, C). Infatti, riceve uno o più input x, rappresentanti i segnali ricevuti dai dendriti, tali input vengono distribuiti attraverso una funzione di attivazione f(x) restituendo un output y che rappresenta l’assone.
Alla base delle Reti Neurali c’è quindi il concetto di neurone artificiale, che ha la possibilità di ricevere più input e fornire, invece, un solo output. Di conseguenza tali Reti Neurali possono essere intese come un insieme di neuroni artificiali organizzati a più livelli.
Il primo riguarda quello degli input, a cui segue un livello intermedio (hidden layer) e infine il livello legato all’output. Ad ogni livello corrispondono uno o più neuroni comunicanti tra loro, infatti l’output di un livello rappresenta l’input di quello successivo.
Ogni unità neurale è connessa con molte altre e i collegamenti possono essere di tipo rafforzativo o inibitorio in relazione all’attivazione delle unità con cui è interconnesso.
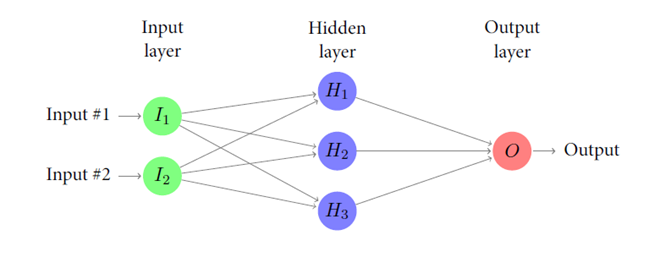
La figura sopra indicata schematizza il funzionamento dei vari livelli. I segnali di ingresso attraversano la rete partendo dal livello di input per arrivare a quello di output, tramite il livello intermedio. Ogni nodo rappresenta un neurone artificiale e le frecce sono i collegamenti tra i neuroni posti sui vari livelli.
Inoltre, quando i livelli nascosti delle Reti Neurali Artificiali o Artificial Neural Network (ANN) sono più di uno e organizzati secondo una struttura gerarchica, entriamo nel mondo del Deep Learning (o Deep Neural Network), la cui peculiarità è quella di rendere condivisibili e utilizzabili le informazioni.
Modelli e struttura del Deep Learning
Generalmente il Deep Learning viene inteso come una diramazione del Machine Learning orientata verso la modellazione di astrazioni di alto livello sui dati[8].
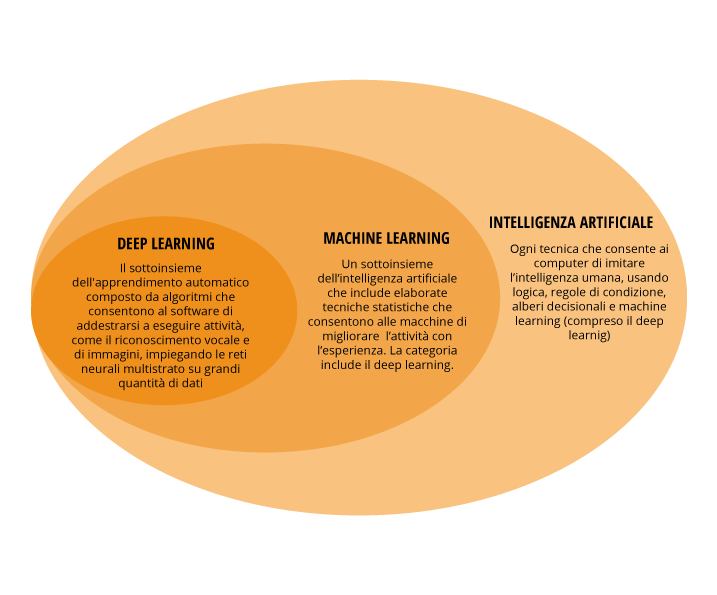
Infatti, le tecniche di Deep Learning sono riconducibili a rappresentazioni dei dati su diversi livelli di astrazione e sono correlati a modelli computazionali a struttura stratificata.
Il Deep Learning, in sostanza, riguarda i modelli di apprendimento della rappresentazione (Representation-learning methods) a livelli multipli, dove ognuno è il risultato della composizione di moduli semplici ma non lineari.
Ogni modulo, partendo da dati ancora grezzi, aggiunge alla rappresentazione una maggiore astrazione, passando da un livello all’altro. In questo modo i livelli di rappresentazione più elevati hanno la possibilità di amplificare le informazioni, eliminando invece quelle superflue. Questa modalità di analisi ha permesso al Deep Learning di scoprire strutture complesse presenti nei Big Data, portando innovazione in diversi settori, come il riconoscimento di immagini, la localizzazione di oggetti e la genetica.
Le architetture del Deep Learning sono raggruppabili in 3 categorie, ognuna con specifiche tecniche di apprendimento:
- Architetture generative: modellano la struttura e distribuzione probabilistica delle singole classi all’interno dei dati. (es. nel caso di un semplice classificatore in grado di distinguere fra immagini di cani e gatti, i modelli generativi “imparano” le caratteristiche di cani e gatti e usano tale conoscenza per distinguerli).
- Architetture discriminative: modellano il decision boundary che meglio separa le due classi all’interno dei dati. (es. continuando l’esempio precedente “imparano” la differenza fra cani e gatti ed utilizzano tale conoscenza per distinguerli).
- Architetture ibride: combinano modelli generativi e discriminativi per ottenere i vantaggi di entrambi i metodi e migliorare le performance generali.
Strumenti e applicazioni
I migliori strumenti di Machine Learning per Data Scientist e Sviluppatori
Gli strumenti di Machine Learning per l’elaborazione di modelli impiegati nell’analisi dei Big Data e l’applicazione degli algoritmi sono molteplici e spesso richiedono una formazione prettamente informatica con una profonda conoscenza dei linguaggi di programmazione.
Tuttavia, visto il crescente interesse verso questo ramo dell’Intelligenza Artificiale, sono sempre più diffusi strumenti messi a disposizione dai colossi aziendali del settore, come Google, Microsoft, IBM e AWS, con l’obiettivo di dare la possibilità di creare servizi e sistemi di apprendimento automatico in modo semplice e automatizzato, facilitando in questo modo, anche la comprensione delle complesse strutture degli algoritmi.
Riportiamo di seguito una selezione dei principali strumenti ad oggi presenti sul mercato:
- Apache PredictionIO è un server di Machine Learning che consente di creare applicazioni AI e modelli predittivi. Si basa su uno stack open source e ha lo scopo di semplificare lo sviluppo di tecnologie di ML. Infatti, non solo unisce e integra i dati di più piattaforme in batch o tempo reale, ma mette a disposizione anche una serie di template preimpostati per la creazione di modelli ML.
- Accord.NET è un framework utilizzato per il calcolo scientifico in .NET., ed è composto da una serie di librerie che comprendono molteplici applicazioni riguardanti l’algebra lineare numerica, statistica, apprendimento automatico, elaborazioni di audio/immagini e rappresentazioni grafiche. E’ utilizzabile su Microsoft Windows, Xamarin, Unity3D, Linux, applicazioni Windows Store e mobile.
- Amazon Machine Learning è un servizio basato su cloud che facilita lo sviluppo di applicazioni scalabili. Infatti, Amazon ML offre strumenti di visualizzazione e procedure guidate per creare modelli predittivi senza la comprensione di complessi algoritmi, grazie anche all’utilizzo di semplici API.
- Amazon SageMaker è una piattaforma interamente su cloud lanciata nel novembre 2017. Fornisce la possibilità di creare, addestrare e distribuire modelli di Machine Learning in cloud su embedded systems e edge-devices.
- AWS API è un servizio AWS che permette di creare, pubblicare, gestire e monitorare un sistema di API di apprendimento.
- è una libreria ideata da Amazon per creare sistemi di apprendimento e addestramento per le reti neurali tramite GPU.
- Azure Machine Learning Workbench è uno strumento ideato per gli sviluppatori e data scientist per la modellazione di sistemi di apprendimento. Tale modellazione può essere in Python, Scala e PySpark ed è supportata da Workbench.
- è una piattaforma di Azure in grado di supportare gli sviluppatori a definire processi di Machine Learning, tramite una serie di funzionalità legate alla modellazione, che vanno dal controllo versione fino alla verifica e distribuzione del modello.
- Caffe è un framework open source di deep learning, scritto in C++ con interfaccia Python.
- IBM Watson Analytics è un servizio cloud fornito da IBM dal 2014 per aiutare le aziende ad aumentare le proprie competenze in termini di analisi predittiva partendo dai dati in possesso.
- NEON è una libreria open source di Machine Learning scritta in Python, ed è stata acquisita da Intel nel 2016.
- Wise.io è un’applicazione di Machine Learning ideata per aiutare le aziende a trovare modelli e informazioni all’interno dei propri dati aziendali ed è di proprietà della General Electric.
- Google TensorFlow è una libreria messa a disposizione da Google in open source per l’apprendimento automatico, che fornisce moduli sperimentati e ottimizzati utili per la realizzazione di algoritmi legati a compiti percettivi e di comprensione. Può fornire diagrammi in C++ o Python (elaborabili in CPU o GPU).
- Google API è un servizio presente sulla piattaforma di Google Cloud e offre la possibilità di utilizzare API per il Machine Learning (tra cui Prediction API che permette di creare algoritmi per l’analisi dati ed elaborazione di modelli predittivi).
- Microsoft Toolkit (DMTK) è un progetto open source di Microsoft che nasce con l’idea di fornire un toolkit tramite il quale è possibile utilizzare gli algoritmi di Microsoft, semplificando così l’esecuzione contemporanea di molteplici applicazioni.
- Microsoft Computational Network Toolkit (CNTK) è un toolkit open source che permette di realizzare vari tipi di modelli di apprendimento e sistemi di reti neurali che sono descritti, tramite un grafo diretto, come una serie di elementi computazionali.
- Apache Spark MLlib e Singa: Apache Spark offre una libreria di algoritmi necessari per l’elaborazione dei dati e di modelli predittivi, mentre Singa è un framework open source presente nell’incubatore Apache e fornisce strumenti di programmazione per le tecniche ML (Deep Learning).
- Veles è una piattaforma di Samsung Elettronics e fornisce strumenti per la creazione di tecniche di Deep Learning. Presenta modelli già pronti per l’analisi dei dati.
- Alibaba Aliyun è la piattaforma di Alibaba per lo sviluppo di software per gli analytics, tramite servizi di cloud computing.
- BigML è un software standardizzato che, tramite tecniche di cloud computing, offre servizi per il Data Analyitcs. È stato ideato da BigML, una delle start up in ambito AI più importanti sul mercato.
Come abbiamo visto, gli strumenti per poter applicare le tecniche di Machine Learning sono numerosi e risulta fondamentale, vista la natura complessa di questa branca dell’Intelligenza Artificiale, scegliere lo strumento più adatto, tenendo conto della specifica struttura degli algoritmi che compongono i vari sistemi di apprendimento automatico.
Ambiti applicativi
In un contesto sempre più connesso, la quantità di dati a disposizione, raccolti quotidianamente, ha assunto un ruolo fondamentale proprio per il valore informativo che questi Big Data portano con sé.
Come già evidenziato, per poter analizzare i cosiddetti Big Data, ad oggi, le tecniche del Machine Learning sono oggetto di studio in svariati settori, dalla medicina all’economia fino ad arrivare anche alle attività correlate al settore compliance.
I campi di applicazione del Machine Learning sono potenzialmente infiniti, a dimostrazione di come le tecniche di Intelligenza Artificiale siano flessibili e mutabili a seconda della tipologia di dato che viene analizzato.
Considerando che le evoluzioni del contesto stanno ampliando il perimetro di analisi e di intervento, con un impiego sempre maggiore di capitale e risorse, il Machine Learning potrebbe avere un ruolo fondamentale nell’ottimizzazione dell’intero processo di individuazione di modelli comportamentali o di efficientamento sistemistico.
Facendo riferimento alle attività di ricerca e sviluppo di
Sadas, parlando di Intelligenza Artificiale, abbiamo diretto riscontro che
l’applicazione delle tecniche di Machine Learning nell’elaborazione dei Big
Data può essere impiegata anche nei mercati di riferimento in cui opera
Sadas.
[1] “The Logic Theory Machine. A complex information processing system”, Allen Newell, Herbert A. Simon, Cliff Shaw, 15 Giugno 1956
[2] “Artificial intelligence: The next digital frontier?” J. Bughin, E. Hazan, S. Ramaswamy, M. Chui, T. Allas, P. Dahlstrom, N. Henke, M. Trench, McKinsey&Company, 2017
[3] “Ue lancia piano intelligenza artificiale da 20 miliardi l’anno”, ANSA, 7 Dicembre 2018
[4] “Pattern Classification and Scene Analysis”, Duda, R. O. & P. E. Hart, New York, 1973
[5] “Regression with a Binary Dependent Variable, in Introduction to Econometrics”, James H. Stock e Mark W. Watson, 3ª ed.,Pearson, 2015
[6] “Top 10 algorithms in data mining”, Xindong Wu, Vipin Kumar, Quinlan J. Ross, J. Ghosh, Qiang Yang, H. Motoda, G. McLachlan, Angus Ng, Bing Liu, Philip S. Yu, Zhi Hua Zhou, M. Steinbach, D. Hand, D. Steinberg, Knowledge and Information Systems, 2008
[7] “ASUM-DM: Analytics Solutions Unified Method for Data Mining/Predictive Analytics”, IBM, 2015
[8] “A Fast Learning Algorithm for Deep Belief Nets”, G. E. Hinton, S. Osindero e Y.-W. Teh, Neural Computation, 2006