

Leasing Score Prediction – La valutazione dei finanziamenti si evolve grazie all’applicazione di modelli di Machine Learning.
Un progetto di collaborazione tra Assilea, Sadas e l’Università di Pisa
Come riportato anche da vari articoli presenti LeaseNews, con dovizia di dati e punti di vista degli operatori, la fase che sta attraversando il mercato del leasing è delicata, perché caratterizzata da una evidente ripresa ma anche da elementi di criticità derivanti dal persistere di condizioni generali che possono portare a nuove insolvenze. Dotarsi di strumenti per una efficace valutazione del merito creditizio in fase di contrattualizzazione e il successivo presidio del portafoglio tramite monitoraggio ed early warning diventa quindi elemento determinante per la salute delle Società di Leasing.
Ad inizio 2020, Assilea, facendo leva sul rilascio del nuovo portale Statistiche realizzato da Sadas con la collaborazione, in fase di analisi, di un gruppo di lavoro di Associate Assilea e sotto la direzione del Centro Studi, ha approfittato delle operazioni di razionalizzazione e rinforzato governo dei dati per analizzare con Sadas possibili sviluppi innovativi basati sull’applicazione di modelli di Machine Learning, da offrire al mercato del leasing che mensilmente alimenta le basi dati Assilea.
Dal confronto tra l’Associazione e il Dott. Roberto Goglia (CEO e Owner di Sadas, software house data-centric del gruppoAS) è maturata la decisione di avviare un progetto comune, con il coinvolgimento del Dipartimento di Informatica dell’Università di Pisa, da sempre partner scientifico di Sadas, e in particolare del Professor Salvatore Ruggieri che, insieme al suo gruppo di ricerca, anche esso coinvolto nell’iniziativa, rappresenta uno dei massimi esperti sulla applicazione di tecniche AI all’analisi dei dati con particolare attenzione ai temi della trasparenza, equità e spiegabilità in ossequio alle disposizioni di EBA, BCE, Banca d’Italia e della recente proposta di regolamentazione Europea dell’AI.
Il progetto è nato e si è sviluppato sulla convinzione che la messa a fattor comune dei dati conferiti dalle Associate alla BDCR (Banca Dati Centrali Rischi del Leasing) potesse essere la precondizione ideale per lo sviluppo di modelli di valutazione del merito creditizio, basati su tecniche di Machine Learning e addestrati su dati dell’intero sistema Leasing italiano e non su dati della singola società. I modelli si applicano sia nell’iter di valutazione della singola operazione in fase di concessione del leasing, sia nella fase di post-avvio come sistema di monitoraggio predittivo di portafoglio ed early warning, in grado di offrire supporto alle decisioni delle Società di Leasing Associate.
Entrando maggiormente in dettaglio, il progetto consiste nello studio e nella realizzazione di un servizio di scoring e di valutazione del merito creditizio per il supporto alle decisioni:
- Specifico per il mondo leasing;
- Basato sull’applicazione di algoritmi di Machine Learning e Big data analytics;
- Erogato da Assilea per le associate on-demand;
- Costruito sull’integrazione del patrimonio informativo della BDCR e di fonti dati esterne:
- Vivo e attuale, in grado di rinnovarsi con i nuovi dati;
- Interrogabile sia per la valutazione di singole posizioni sia per l’analisi di portafogli contratti;
- In grado di fornire spiegazioni degli score assegnati secondo il principio di trasparenza.
Si tratta di un servizio da applicare sia in fase di valutazione del rischio prima della stipula di uno specifico contratto, sia nella fase di valutazione del rischio durante la vita di un contratto (cosiddetto early-warning).
Come tutti i progetti di Machine Learning guidati da Sadas, il processo di implementazione del progetto è stato ispirato all’ASUM-DM (Analytics Solutions Unified Method – Data Mining) e ha previsto cinque macrofasi:
Analyze – Design – Configure&Build – Deploy – Operate&Optimize.
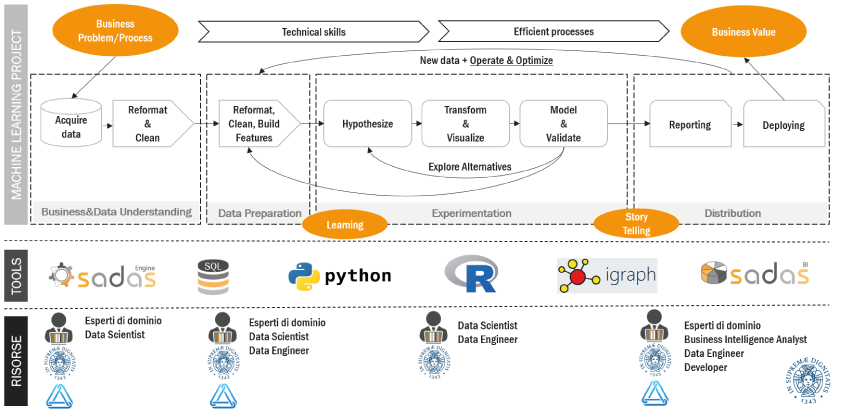
In particolare, nel Q1-2020 il team si è dedicato alle delicate fasi di Business Understanding e Data Understanding, alla definizione del processo sperimentale di backtesting (Rolling Method), alla definizione, calcolo e selezione di attributi predittivi per i contratti alla stipula (Data Preparation).
Nel Q2-2020 le attività sono state finalizzate alla definizione delle metriche di valutazione, all’ottimizzazione e al confronto di performance predittive di differenti modelli di Machine Learning, alla fase di Data Enrichment ovvero all’estrazione e alla selezione di attributi predittivi da sorgenti esterne alla BDCR (indici di demografia aziendale di fonte Camere di Commercio, voci e indicatori di bilancio e informazioni anagrafiche di fonte Cerved), alla sperimentazione/personalizzazione di algoritmi per la spiegazione delle predizioni dei modelli (LIME, SHAP, LORE, ecc.) propagata anche nei due quarter successivi.
A partire dal Q3-2020, sono partite le due attività critiche di sperimentazione estensiva del modello selezionato (LightGBM, appartenente alla famiglia dei decision tree boosting algorithms) e sperimentazione/personalizzazione di algoritmi per la determinazione di controfattuali azionabili (DICE, MACE/AR, FACE, DCE, ensemble di approcci, ecc.). Queste attività hanno impegnato il gruppo fino al Q2-2021 concluso con lo story-telling verso il gruppo di lavoro e la definizione delle modalità di deploy e utilizzo della soluzione in produzione, la quale sarà accessibile alle Associate tramite interrogazione del portale BDCR o integrata nei processi operativi aziendali per la valutazione sia di soggetti censiti che non censiti in BDCR.
Particolare attenzione è stata dedicata agli aspetti di spiegabilità degli score. Gli strumenti di analisi predittiva devono essere intesi a supporto del valutatore, e, come tali, le motivazioni sottostanti un determinato score devono essere chiaramente esplicitate. Quali variabili predittive contribuiscono a determinare lo score in uno specifico caso in esame? Quali variazioni alle condizioni contrattuali porterebbero ad uno score più favorevole? La prima risposta, detta spiegazione fattuale, supporta l’assegnazione dello score, e permette al valutatore di prendere in considerazione fattori che emergono dalla storia dei dati di addestramento, ben oltre quindi l’esperienza individuale per quanto ampia. La seconda risposta, detta spiegazione controfattuale, permette al valutatore di considerare varianti per poter recuperare un contratto che altrimenti andrebbe declinato, ma che si posiziona vicino al confine tra score positivo e negativo. Tali varianti dovrebbero essere scelte tra quelle realisticamente implementabili, dette azionabili, come ad esempio un allungamento del periodo, o la presenza di una garanzia aggiuntiva.
“Il machine learning è una modalità di apprendimento basata sull’analisi dei dati, una branca dell’Intelligenza Artificiale basata sull’idea che i sistemi possano imparare dai dati storici rilevando e astraendo dai comportamenti osservati per ottenere modelli previsionali. È il punto di convergenza di expertise di dominio e di business, statistica, matematica, big data, computer science, è il punto di vista di chi non solo guarda al passato (What happened? – Descriptive Analytics) cercando di spiegare a posteriori il perché (Why did it happen? – Diagnostic Analytics), ma di chi ha l’ambizione di prevedere, con una certa confidenza, cosa accadrà in un orizzonte temporale definito (What will happen? – Predictive Analytics) e quali strategie mettere in atto affinché accada (How can we make it happen? – Prescriptive). I modelli sviluppati dal gruppo di lavoro rispondono esattamente a queste ambiziose domande con periodicità trimestrale: quando il motore di Machine Learning viene alimentato con nuovi dati, i modelli vengono ri-addestrati adattandosi ad essi e scoprendo i nuovi pattern fino a quel momento sconosciuti, con l’obiettivo di massimizzare la capacità predittiva”.
Dott. Roberto Mosca
Head of Advanced Analytics & Machine Learning, Sadas
Per conto di Assilea, il Dott. Andrea Beverini aggiunge:
“Crediamo che, con la realizzazione di questo nuovo Score, la BDCR farà un notevole salto in avanti riaffermando il proprio ruolo primario nell’ambito dell’analisi creditizia e nell’attività di monitoraggio della qualità del proprio portafoglio clienti. Conoscere in anticipo le probabili rischiosità di una nuova operazione o intravedere future problematiche dei contratti consentiranno alle Associate di operare in sicurezza e collaborare responsabilmente con e per la propria clientela. L’utilizzo di algoritmi predittivi allenati “on going” con tecniche di ML siamo certi che saranno apprezzati in primis dai nostri Associati e garantiranno alla nostra BDCR di tornare ad occupare un posto prioritario nella classifica dei SIC italiani scelti e utilizzati per l’attività di valutazione della capacità creditizia.”
Tra i rappresentanti delle società di Leasing associate che hanno preso parte al gruppo di lavoro, il Dott. Ugo Mauro, Responsabile Organizzazione e Controllo di BCC Lease, riporta:
“Valutiamo con grande attenzione tutte le iniziative legate all’AI e per questo motivo, non solo abbiamo risposto tempestivamente all’Associazione in fase di definizione del gruppo di lavoro, ma abbiamo anche deciso di collaborare attivamente al raggiungimento degli obiettivi. I risultati sono estremamente interessanti sia in termini di capacità predittiva che di spiegabilità e siamo certi che i modelli sviluppati per l’analisi del rischio in fase di delibera di nuove operazioni e per la generazione di early warning per i contratti avviati, apporteranno un consistente contributo all’interno dei nostri sistemi di valutazione.”
La collaborazione tra le diverse entità coinvolte è stata determinante per indirizzare i lavori in una direzione che producesse dei risultati utili a tutto il sistema Leasing grazie alle esperienze e competenze di Sadas e dell’Università di Pisa, sfruttando il patrimonio informativo conferito dalle società di Leasing alla Associazione.
Ogni ente coinvolto ha contribuito con le proprie specifiche competenze, conoscenze e possibilità a disposizione per il raggiungimento degli obiettivi del progetto. L’Università di Pisa ha contribuito con la competenza accademica nell’impostazione del processo analitico, nella valutazione delle soluzioni tecniche anche in confronto con la letteratura scientifica, nella validazione dei risultati, con particolare attenzione ai temi, in questo momento ancora ambito di intensa ricerca, della trasparenza e spiegabilità dei risultati. Le società di Leasing, partecipanti al progetto tramite un gruppo di lavoro ristretto, hanno definito requisiti, condiviso esperienze, fornito business case e revisionato i risultati. Sadas ha fornito competenze, ambienti di lavoro, risorse umane, investendo per oltre due anni nel progetto e finanziando le attività dell’Università, mentre L’Associazione ha messo a disposizione i dati della BDCR, coordinando e sovrintendendo le attività, nel rispetto delle normative e degli accordi.
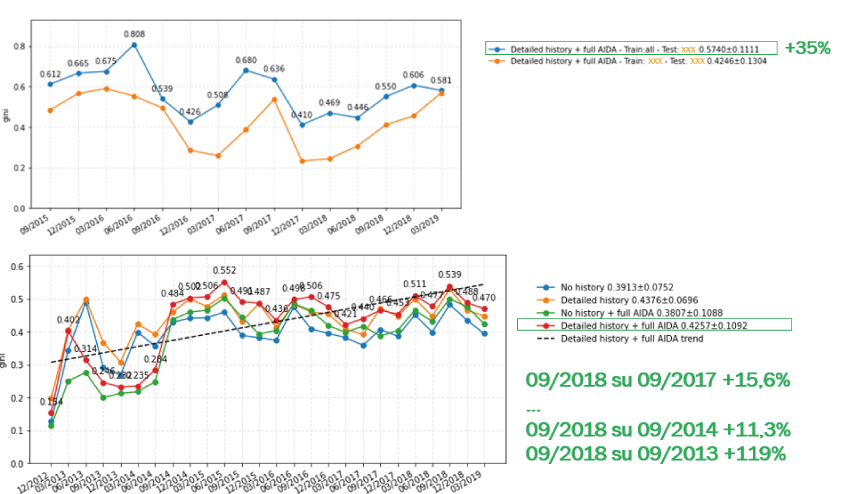
Il team ha condotto circa 5.000 esperimenti sui contratti alla stipula combinando set di variabili (features) in tempi diversi e addestrando modelli su variabile target, oggetto da prevedere, definita in funzione di gravità (contenzioso, insolvenza grave, insolvenza leggera) e periodo di lookahead (tempo massimo in mesi entro il quale l’evento target può manifestarsi, 12/24/36/48 mesi) con risultati, in termini di Gini[1], apprezzati dal gruppo di lavoro e più che in linea con quelli pubblicati in letteratura e che si attestano, come illustrato nella figura 2, su un valore medio di 0,574 ± 0,1111 con picchi positivi superiori a 0,8 e mai al di sotto di 0,410.
Dagli esperimenti è emerso che:
- le singole associate traggono significativi benefici [+8%,+inf] dalla messa a fattor comune dei dati storici (la variazione a +inf si riferisce a quelle Associate per le quali, per i dati in possesso del gruppo di lavoro, non sarebbe stato possibile sviluppare un modello previsivo senza il contributo delle altre);
- la disponibilità di indicatori di bilancio, per le aziende per cui sono previsti, migliorano significativamente le performance predittive [circa +20%];
- il modello risulta ben calibrato[2] e quindi idoneo a trattare gli score di rischio come probabilità;
- l’utilizzo combinato di informazioni anagrafiche su soggetti coinvolti, sull’operazione, di indicatori di bilancio e di dati comportamentali storici su conduttori, determina la migliore calibrazione;
- l’utilizzo dei dati storici puntuali massimizza le capacità predittive [+15%,+20%] rispetto all’uso di dati storici in forma aggregata;
- le performance migliorano nel tempo (a parità di set di features) confermando l’importanza di una base dati storica per l’addestramento del modello di Machine Learning [incremento superiore +100% del modello addestrato nel Settembre 2018 rispetto al modello addestrato nel Settembre 2013]. Inoltre, le performance sono ancora potenzialmente migliorabili con l’inserimento di nuovi set di dati di fonte interna ed esterna;
- il modello migliore è ottenuto dalla combinazione con orizzonte temporale di previsione pari a 12 mesi ed evento target da predire pari ad insolvenza grave o contenzioso;
- esiste la possibilità di massimizzare le performance individuando nicchie di casi su cui il modello è mediamente più accurato al costo di restringere il raggio di azione del modello stesso;
- l’aumento della qualità del dato migliora le performance predittive [circa +5%];
- indicatori di demografia aziendale (fonte Camera di Commercio delle Marche) e features su storia aggregata dei conduttori (BDCR) introducono rumore nei modelli peggiorando le performance. Essi sono quindi stati esclusi.
I risultati raggiunti, riferiti alla fase di pre-contrattualizzazione, ovvero all’analisi del rischio alla stipula, sono stati apprezzati dal gruppo di lavoro che sta ragionando sulla modalità più opportuna per l’integrazione di questi nuovi strumenti offerti dall’Associazione all’interno dei propri sistemi. Come noto, la BDCR viene alimentata dai soli contratti stipulati. Conseguentemente i modelli di Machine Learning sono addestrati e valutati sulla predizione del rischio per i contratti che passano la fase di istruttoria. La partecipazione attiva del gruppo di lavoro, mediante la condivisione di un campione di contratti declinati (rejected), permetterà di verificare la capacità di generalizzazione dei modelli di Machine Learning addestrati anche su contratti non stipulati, e quindi di sperimentarne l’uso anche in una fase precedente del processo di valutazione del merito creditizio.
Proprio per le loro tipicità in fieri, i modelli di Machine Learning si caratterizzano per la capacità di adattarsi a nuovi comportamenti del mercato e ai conseguenti cambiamenti nei dati (dataset shift). La rapidità di taluni eventi, dovuti per esempio all’emergenza per COVID-19, richiede però azioni immediate nel processo di addestramento dei modelli al fine di anticipare il riconoscimento, ad esempio, delle moratorie del credito. Questo è stato possibile integrando nel dataset di addestramento le informazioni provenienti dalla BDCR sui periodi di moratorie.
In conclusione, il processo di definizione dei modelli di Machine Learning può essere inteso come un arricchimento continuo. Difatti il gruppo di lavoro sta sperimentando nuovi modelli per il monitoraggio di posizioni in essere (singole, di portafoglio, cluster) e la generazione di early warning con risultati davvero interessanti che saranno pubblicati nei prossimi mesi.
Articolo a cura di Roberto Mosca, Head of Advanced Analytics & Machine Learning, Sadas
Fiera del credito, 15 giugno 2022 – E’ stato presentato al pubblico Leasing Score Prediction, il modello statistico avanzato realizzato in collaborazione con Assilea, addestrato con tecniche di Machine Learning e finalizzato a supportare le società di leasing a migliorare la qualità del portafoglio contratti. Il Leasing Score Prediction, allarga la prospettiva di valutazione del finanziamento, suggerisce diversi set di parametri alternativi che possono migliorare lo score previsionale e sarà a breve disponibile anche per il monitoraggio periodico di portafoglio.
Press
ADNKRONOS – Assilea presenta 5 progetti per la crescita economica
LeaseNews – SOSTENIBILITA’ AMBIENTALE ED ECONOMICA con il leasing
ANSA – Imprese: Assilea, cinque progetti a sostegno delle pmi
AFN – Assilea presents 5 projects for economic growth
[1] L’indice di Gini rappresenta la metrica usualmente utilizzata per valutare le performance predittive di modelli previsivi ed esprime la frazione delle performance rispetto a quelle del predittore perfetto (o “oracolo”).
[2] Un modello (statistico o di Machine Learning) è ben calibrato se uno score di rischio predetto dal modello può essere interpretato come probabilità (in particolare, probabilità di default).